Redis(一)
本文最后更新于 2024年9月8日 晚上
Redis(一)
1. 介绍下Redis以及Redis有哪些数据类型
Redis全称(Remote Dictionary Server)本质上是一个Key-Value类型的内存数据库,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。
常用的基本数据类型
数据类型 介绍 编码方式 String 字符串(一个字符串类型最大存储容量为512M)({hello world}) INT、EMBSTR、RAW List 可以重复的集合 ({A -> B -> C -> C}) ZIPLIST、LINKEDLIST Set 不可以重复的集合 ({A, B, C}) Hash 类似于Map<String,String> ({name: “Jack”, age: 21}) SortedSet 带分数的set ({A: 1, B: 2, C: 3}) 基本操作:
String:
写操作
SET
1
2127.0.0.1:6379> set test myTest
OKset 还可另加几个参数:
EX second:设置键的过期时间为多少秒
PX millisecond:设置键的过期时间为多少毫秒
NX:只有键不存在时才对键进行操作,相当于 SETNX key value
XX:只有键存在时才对键进行操作
使用示例:
1
2
3
4127.0.0.1:6379> set test myTest EX 60
OK
127.0.0.1:6379> ttl test
(integer) 57
SETNX
用于在指定的 key 不存在时设置 key 的值。返回值 1 表示设置成功,0表示不做修改。
用法:SETNX key value
使用示例:
1
2
3
4127.0.0.1:6379> SETNX test myTest
(integer) 1
127.0.0.1:6379> SETNX test myTest0
(integer) 0
DEL
删除对象,返回值为删除了几行
用法:DEL key [key …]
示例:
1
2127.0.0.1:6379> del test
(integer) 11
2127.0.0.1:6379> del test test1
(integer) 2
读操作:
GET
- 获取某个 key 的 value,不存在则返回 nil
- 用法:get key
MGET
- 一次获取多个 key 的 value,不存在则返回 nil
List:
写操作:
LPUSH
从头部增加元素,返回为 list 中的元素总数
用法:LPUSH key value [value …]
示例:
1
2
3
4
5
6
7
8
9127.0.0.1:6379> LPUSH testList test1 test2 test3
(integer) 3
127.0.0.1:6379> LPUSH testList test4
(integer) 4
127.0.0.1:6379> LRANGE testList 0 4
1) "test4"
2) "test3"
3) "test2"
4) "test1"
RPUSH
从尾部增加元素,返回为 list 中的元素总数
用法:RPUSH key value [value …]
示例:
1
2
3
4
5
6
7
8
9127.0.0.1:6379> RPUSH testList test1 test2 test3
(integer) 3
127.0.0.1:6379> RPUSH testList test4
(integer) 4
127.0.0.1:6379> LRANGE testList 0 4
1) "test1"
2) "test2"
3) "test3"
4) "test4"
LPOP
移出并获取列表中的第一个元素
用法:LPOP key
示例:
1
2127.0.0.1:6379> LPOP testList
"test1"
RPOP
移出并获取列表中的最后一个元素
用法:RPOP key
示例:
1
2127.0.0.1:6379> RPOP testList
"test4"
LREM
用法:LREM key count value
移出值等于 value 的元素。当 count = 0 时,移除所有等于 value 的元素。当 count > 0 时,则从左到右移除 count 个元素,当 count < 0 则从右到左移除 count 个。返回值为被移除元素的数量。
示例:
1
2127.0.0.1:6379> LREM testList 1 test2
(integer) 1
DEL
- 删除对象,返回值为删除了几个键
- 用法:del key [key …]
UNLINK
- 删除对象,返回值为删除了几个键
- 用法:unlink key [key …]
- 与 DEL 命令的区别:DEL 命令时同步删除命令,会阻塞客户端直到删除完成。UNLINK命令是异步删除命令,只是取消 key 在键空间的关联,让其不能再查到,删除是异步进行,所以不会阻塞客户端。
读操作:
LLEN
获取 list 的长度,即元素个数
用法:LLEN key
示例:
1
2127.0.0.1:6379> LLEN testList
(integer) 3
LRANGE
用法:LRANGE key start stop
查看 start 到 stop 的元素
示例:
1
2
3
4127.0.0.1:6379> LRANGE testList 0 3
1) "test3"
2) "test2"
3) "test1"
Set
写操作
SADD
用于向集合中添加元素,返回值为添加了几个元素
用法:SADD key member [member …]
示例:
1
2
3
4
5
6127.0.0.1:6379> SADD testSet aa bb cc
(integer) 3
127.0.0.1:6379> SMEMBERS testSet
1) "cc"
2) "bb"
3) "aa"
SREM
删除集合中的元素,返回值为删除了几个元素
用法:SREM key member [member …]
示例:
1
2127.0.0.1:6379> SREM testSet aa
(integer) 1
读操作
SISMEMBER
查询某个 key 是否存在于集合中,存在返回 1,不存在返回 0
用法:SISMEMBER key member
示例:
1
2
3
4127.0.0.1:6379> SISMEMBER testSet aa
(integer) 0
127.0.0.1:6379> SISMEMBER testSet bb
(integer) 1
SCARD
查询集合元素个数
用法:SCARD key
示例:
1
2127.0.0.1:6379> SCARD testSet
(integer) 2
SMEMBERS
查看集合的所有元素
用法:SMSMBERS key
示例:
1
2
3127.0.0.1:6379> SMEMBERS testSet
1) "cc"
2) "bb"
SSCAN
查看集合元素,可以理解为指定游标进行查询,可以指定个数,默认为 10
用法:SSCAN key cursor [MATCH pattern] [COUNT count]
示例:
1
2
3
4127.0.0.1:6379> SSCAN testSet 0
1) "0"
2) 1) "cc"
2) "bb"1
2
3127.0.0.1:6379> SSCAN testSet 0 MATCH c* COUNT 2
1) "3"
2) 1) "cc"
SINTER
返回在第一个集合中,且同时后面所有集合都共有的元素
用法:SINTER key [key …]
示例:
1
2
3
4
5
6
7
8
9
10
11127.0.0.1:6379> SMEMBERS testSet
1) "cc"
2) "bb"
127.0.0.1:6379> SMEMBERS testSet2
1) "dd"
2) "cc"
3) "bb"
4) "aa"
127.0.0.1:6379> SINTER testSet testSet2
1) "cc"
2) "bb"
SUNION
返回所有集合的并集
用法:SUNION key [key …]
示例:
1
2
3
4
5127.0.0.1:6379> SUNION testSet testSet2
1) "dd"
2) "bb"
3) "cc"
4) "aa"
SDIFF
返回第一个集合有,后面集合不存在的元素
用法:SDIFF key [key …]
示例:
1
2
3127.0.0.1:6379> SDIFF testSet2 testSet
1) "dd"
2) "aa"
Hash
写操作
HSET
添加或更新 (field, value)
用法:HSET key field value [field value …]
示例:
1
2
3
4
5127.0.0.1:6379> HSET testHash test1 aaaa
(integer) 1
127.0.0.1:6379> HGETALL testHash
1) "test1"
2) "aaaa"1
2127.0.0.1:6379> HSET testHash test3 ccccc test4 ddddd
(integer) 2
HSETNX
如果 field 不存在,则添加 (field, value)
用法:HSETNX key field value
示例:
1
2
3
4127.0.0.1:6379> HSETNX testHash test1 bbbb
(integer) 0
127.0.0.1:6379> HSETNX testHash test2 bbbb
(integer) 1
HDEL
- 删除指定 field
- 用法:HDEL key field [field …]
DEL
- 删除 Hash 对象
- 用法:DEL key
HMSET
- 设置多个键值对,类似于 HSET
- 但是在 Redis 4.0.0 后 HMSET 已经被弃用,直接使用 HSET 即可
读操作
HGETALL
查找全部数据
用法:HGETALL key
示例:
1
2
3
4
5
6
7
8
9127.0.0.1:6379> HGETALL testHash
1) "test1"
2) "aaaaa"
3) "test2"
4) "bbbbb"
5) "test3"
6) "ccccc"
7) "test4"
8) "ddddd"
HGET
查找 field 对应的 value
用法:HGET key field
示例:
1
2127.0.0.1:6379> HGET testHash test1
"aaaaa"
HLEN
查找 Hash 中元素总数
用法:HLEN key
示例:
1
2127.0.0.1:6379> HLEN testHash
(integer) 4
HSCAN
- 从指定位置查询一定数据
- 用法:HSCAN key cusor [MATCH pattern] [COUNT count]
ZSet
写操作
ZADD
向 Sorted Set 添加数据或更新数据
用法:ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member …]
示例:
1
2127.0.0.1:6379> ZADD testZSet 1 aaa 2 bbb 3 ccc
(integer) 3扩展:
- XX:仅更新存在的成员,不添加新成员。
- NX:不更新存在的成员,只添加新成员。
- LT:更新新的分值比当前分值小的成员,不存在则新增。
- GT:更新新的分值比当前分值大的成员,不存在则新增。
- CH:改变返回值的计算逻辑。默认返回的是新添加的元素个数,提供该参数后返回被改变的元素个数:即新增的元素个数和score值被更新的元素个数之和。如果元素已经存在,且新的score值与当前score值一样,不会被计数
- INCR:提供该参数后的命令类似
ZINCRBY,将score加上一个值,只允许提供一个member和score - 注意:GT/LT 和 NX 的选项是互斥的
ZREM
删除 ZSet 中的元素
用法:ZREM key member [member …]
示例:
1
2127.0.0.1:6379> ZREM testZSet aaa
(integer) 1
读操作
ZCARD
查看 ZSet 中的成员数
用法:ZCARD key
示例:
1
2127.0.0.1:6379> ZCARD testZSet
(integer) 2
ZRANGE
从小到大遍历,WITHSCORES 可选择性加上,不加的话输出就只有 key,没有 score 值。
用法:ZRANGE key start stop [WITHSCORES]
示例:
1
2
3
4
5
6
7
8127.0.0.1:6379> ZRANGE testZSet 0 -1
1) "bbb"
2) "ccc"
127.0.0.1:6379> ZRANGE testZSet 0 -1 WITHSCORES
1) "bbb"
2) "2"
3) "ccc"
4) "3"ps:-1 代表最后一个元素位置
ZREVRANGE
从大到小遍历,WITHSCORES 可选择性加上,不加的话输出就只有 key,没有 score 值。
用法:ZREVRANGE key start stop [WITHSCORES]
示例:
1
2
3
4
5
6
7
8127.0.0.1:6379> ZREVRANGE testZSet 0 -1
1) "ccc"
2) "bbb"
127.0.0.1:6379> ZREVRANGE testZSet 0 -1 WITHSCORES
1) "ccc"
2) "3"
3) "bbb"
4) "2"
ZCOUNT
用法:ZCOUNT key min max
计算 min-max 分数范围内的成员个数
示例:
1
2127.0.0.1:6379> ZCOUNT testZSet 0 2
(integer) 1
ZRANK
用法:ZRANK key member
查看 ZSet 中 member 的排名索引。索引从 0 开始,所以排第一就是 0,而不在 ZSet 里的会返回 (nil)
示例:
1
2
3
4127.0.0.1:6379> ZRANK testZSet aaa
(nil)
127.0.0.1:6379> ZRANK testZSet bbb
(integer) 0
ZSCORE
用法:ZSCORE key member
查询 ZSet 中 member 的分数,不在 ZSet 里的会返回 (nil)
示例:
1
2
3
4127.0.0.1:6379> ZSCORE testZSet aaa
(nil)
127.0.0.1:6379> ZSCORE testZSet bbb
"2"
2. Redis提供了哪几种持久化方式
两种持久化方式特点
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储。
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以 redis 协议追加保存每次写的操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
有关持久化方式
如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式。
你也可以同时开启两种持久化方式,在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
两种持久化方式介绍
RDB持久化:
每隔一段时间,将内存中的数据集写到磁盘
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
保存策略:
save 900 1: 900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10: 300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000: 60 秒内如果至10000 个 key 的值变化,则保存
AOF 持久化:
以日志形式记录每个更新操作
Redis重新启动时读取这个文件,重新执行新建、修改数据的命令恢复数据。
保存策略:
appendfsync always:每次产生一条新的修改数据的命令都执行保存操作;效率低,但是安全!
appendfsync everysec:每秒执行一次保存操作。如果在未保存当前秒内操作时发生了断电,仍然会导致一部分数据丢失(即1秒钟的数据)。
appendfsync no:从不保存,将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
缺点:
比起RDB占用更多的磁盘空间
恢复备份速度要慢
每次读写都同步的话,有一定的性能压力
存在个别Bug,造成恢复不能
对比:
- 体积方面:相同数据情况下,RDB 体积更小,因为 RDB 记录的是二进制紧凑型数据,而 AOF 生成的是文本文件
- 恢复速度:RDB 是数据快照,可以直接加载,而 AOF 文件恢复,相当于重放情况,RDB 会更快
- 数据完整性:AOF 记录了每条日志,RDB 是间隔一段时间记录一次,因此 AOF 的恢复数据通常会更加完整
选择策略:
- 如果是想单纯用 Redis 做访问速度优化这种,可以不需要开持久化。不过这也不是绝对的,具体使用与否还是要看具体情况。
- 官方推荐:如果对数据不敏感,可以选单独用RDB;不建议单独用AOF,因为可能出现 Bug;如果只是做纯内存缓存,可以都不用
- 如果对数据非常重视,可以同时开启 RDB 和 AOF,同时开启的话 RDB 只是备份,实际用的是 AOF,因为 AOF 的一致性是更强的。
- 如果可以接受丢几分钟的数据,那么可以只开 RDB
3. Redis为什么快
完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
使用I/O多路复用模型,非阻塞IO
4. Redis为什么是单线程的
- 官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了Redis利用队列技术将并发访问变为串行访问
绝大部分请求是纯粹的内存操作
采用单线程,避免了不必要的上下文切换和竞争条件
5. 为什么Redis的操作是原子性的,怎么保证原子性的
对于Redis而言,命令的原子性指的是:一个操作的不可以再分,操作要么执行,要么不执行。
Redis的操作之所以是原子性的,是因为Redis是单线程的。
Redis本身提供的所有API都是原子操作,Redis中的事务其实是要保证批量操作的原子性。
多个命令在并发中也是原子性的吗?
- 不一定, 将get和set改成单命令操作,incr 。使用Redis的事务,或者使用Redis+Lua==的方式实现
6. Redis有事务吗
Redis是有事务的,redis中的事务是一组命令的集合,这组命令要么都执行,要不都不执行,
redis事务的实现,需要用到MULTI(事务的开始)和EXEC(事务的结束)命令 ;
当输入MULTI命令后,服务器返回OK表示事务开始成功,然后依次输入需要在本次事务中执行的所有命令,每次输入一个命令服务器并不会马上执行,而是返回”QUEUED”,这表示命令已经被服务器接受并且暂时保存起来,最后输入EXEC命令后,本次事务中的所有命令才会被依次执行,可以看到最后服务器一次性返回了两个OK,这里返回的结果与发送的命令是按顺序一一对应的,这说明这次事务中的命令全都执行成功了。
Redis的事务除了保证所有命令要不全部执行,要不全部不执行外,还能保证一个事务中的命令依次执行而不被其他命令插入。同时,redis的事务是不支持回滚操作的。
7. 缓存击穿,缓存穿透,缓存雪崩的原因和解决方案
缓存穿透:
用户请求的数据在缓存中和在数据库中都不存在,不断发起这样的请求会给数据库带来巨大压力
解决方案:
缓存空对象:空结果也进行缓存,可以设置一个空对象,但它的过期时间会很短,最长不超过五分钟,让这些请求不会到达数据库。
优点:实现简单,维护方便
缺点:
额外的内存消耗
可能造成短期的不一致
使用布隆过滤器也可以解决,Redisson框架中有布隆过滤器。
优点:内存占用较少,没有多余 key
缺点:
实现复杂
存在误判的可能
缓存雪崩:
是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存击穿
是指对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:如果这个key在大量请求同时进来之前正好失效,那么所有对这个key的数据查询都落到DB,我们称为缓存击穿。
解决方案:
互斥锁
优点:
没有额外的内存消耗
保证一致性
实现简单
缺点:
线程需要等待
可能有死锁风险
逻辑过期
- 优点:线程无需等待,性能较好
- 缺点:
- 不保证一致性
- 有额外内存消耗
- 实现复杂
热点key续期
- 优点:线程无需等待,性能较好
- 缺点:
- 不保证一致性
8. String 的三种编码方式
- INT 编码:存储整形,可以用 long 表示的整数就用这个保存
- EMBSTER 编码:如果字符串小于等于阈值字节,就使用 EMBSTER 编码
- RAW 编码:字符串大于阈值字节,则使用 RAW 编码
ps:5.0.5 版本的阈值是44
9. List 对象底层编码
- 3.2 版本之前使用的是 ZIPLIST 和 LINKEDLIST,list 所有字符串长度都小于64且对象元素个数小于512时使用 ZIPLIST,超出限制就使用 LINKEDLIST
- 3.2 及之后版本引入了 QUICKLIST,QUICKLIST 是一个压缩列表组成的双向链表,使用了 ZIPLIST 和 LINKEDLIST 综合的结构取代了二者,避免了 ZIPLIST 的连锁更新问题
- 7.0 之后引入了 LISTPACK 全面替代 ZIPLIST
ps:ZIPLIST 优点是内存利用率很高,可以减少内存碎片
10. Set 对象底层编码
- Redis 的 Set 使用两种编码方式,INSERT 和 HASHTABLE。如果集合元素都是整数且元素数量不超过512,则使用 INSERT 编码
- INSERT:排列比较紧凑,内存占用少,但是查询时需要用到二分查找,是有序的
- HASHTABLE:查询性能很高,时间复杂度是 O(1),是无序的
11. Hash 对象底层编码
- Hash 底层有两种编码,分别是压缩列表和 HASHTABLE。
- 当 Hash 保存的对象的所有值和键的长度都小于64字节且 Hash 对象的元素个数小于 512 个时,使用压缩列表,否则使用 HASHTABLE。
12. ZSet 对象底层编码
- ZSet底层编码有两种,一种是ZIPLIST,一种是 SKIPLIST+HASHTABLE。
- 当列表对象保存的所有字符串对象长度都小于 64 字节且列表对象元素小于 128 个时,使用 ZIPLIST,否则使用 SKIPLIST+HASHTABLE。
13. Redis 数据结构及存储
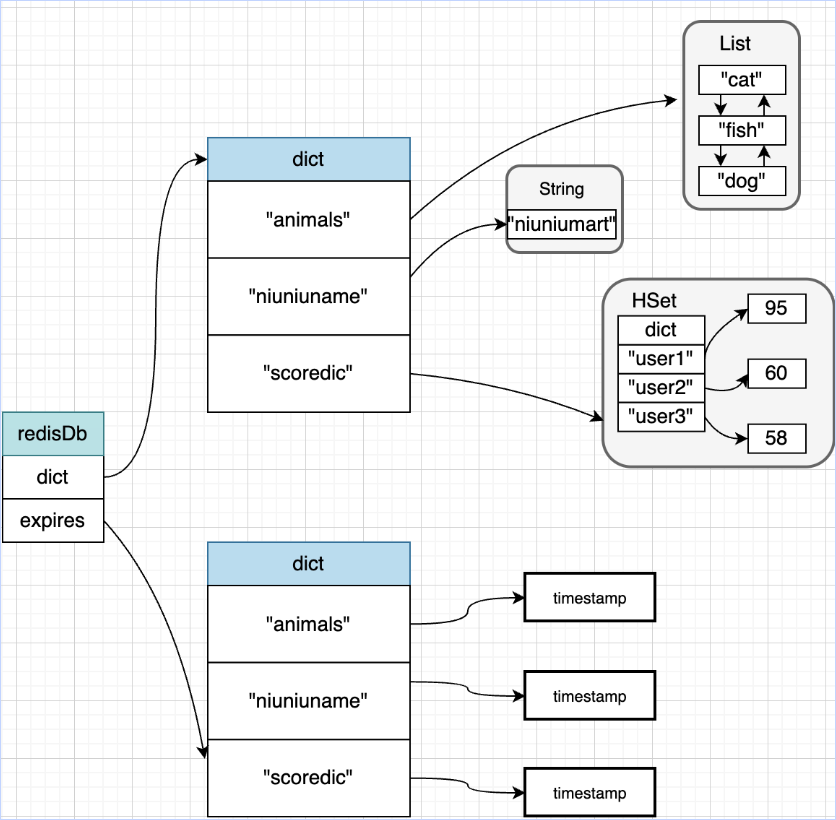
Redis 数据库的结构示例是:
1 | |
顶层是 redisServer,我们知道 redis 有 16 个库,每个库的就是一个 redisDb,而 redisDb 中又存储了 dict 结构
下面是两个重要结构的源码:
1 | |
1 | |
这里的存储逻辑还是很好理解的,redisDb 的 dict 中存储 key,value 存储在 dict 的结构中。
过期时间即 expires,存储在 redisDb 中。
下面一张图即可理解:
14. Redis 是单线程吗
Redis 的核心处理逻辑是单线程的,但是在 4.0 之后加入了异步流程如 UNLINK 这些非阻塞操作。
15. Redis 为什么不用多线程实现?
因为瓶颈一般是 网络I/O 而不是 CPU,这种情况下选则多线程的话实现难度、复杂度和成本都会变高。
16. Redis 的单线程的性能如何?
一般认为是 QPS 10W 多,具体的话得看不同厂商
17. Redis 为什么单线程还这么快?
- Redis 是内存数据库,内存操作本来就很快。
- Redis 使用了高效的数据结构,在底层每个数据类型都有各自的底层编码和优化实现,如 ZSet 中的跳表+HASHTABLE、List 中的 ZIPLIST 和 LINKEDLIST 等,很好的保证了性能。
- Redis 还采用了多路复用的机制,使得在网络请求中能并发处理大量的请求,实现高吞吐量。
18. Redis 的内存淘汰策略
Redis 的默认大小是 1024 (默认字节),也可以在配置文件里修改 maxmemory,maxmemory 支持单位,如:
1024 KB/1024 MB/1024 GB
超过这个值就会触发内存淘汰策略:

19. 内存回收是什么时候发起的?
每次进行读写的时候,都会检查是不是大于 maxmemory 且开启了淘汰策略,如果满足则会触发。
20. 持久化配置
Redis 中有默认配置:
1 | |
格式是:save 时间间隔 写次数
意思是:每段隔一段时间间隔内只要写次数达到了限制,就触发持久化。如 save 900 1 是每 900 秒有一条写操作就触发。另外这些配置是并集的关系,满足一条就触发持久化。
21. 怎么触发持久化
直接输入命令:save
ps:会阻塞主线程,慎用
直接输入命令:bgsave
达到持久化配置的阈值
程序关闭时,Redis 会再执行一次持久化,该次是阻塞的
22. AOF 重写是解决什么问题
是用于解决 AOF 日志不断膨胀问题。随着命令不断变多,日志文件也会越来越大,但是很多数据操作可能都是对同一个数据进行的,比如 set a 1; set a 100;, 这样的话前一个命令 set a 1; 其实就没必要再重复记录,直接覆盖就行。其实重写也就是通过当前状态重新生成最新的 AOF 操作命令记录的过程。
PS:当 AOF 日志文件体积变得过大时,会自动在后台 fork 一个子进程,专门对 AOF 进行重写。
23. AOF 重写流程
- 一次拷贝,两处缓冲
- 一次拷贝:重写发生时主进程会 fork 出一个子进程,子进程和主进程共享物理内存,让子进程将这些内存写入重写日志
- 两处缓冲:当重写时,有新的写入命令执行时,会由主进程分别写入 AOF缓冲 和 AOF重写缓冲,AOF缓冲 负责保证即使此时宕机原来的 AOF日志 也是完整的,可用于恢复,AOF重写缓冲用于保证新的 AOF文件 也不会丢失最新的写入操作。
24. AOF 三种策略
- appendfsync always,每次请求都刷入AOF,用官方的话说,非常慢,非常安全
- appendfsync everysec,每秒刷一次盘,用官方的话来说就是足够快了,但是在崩溃场景下
你可能会丢失1秒的数据。 - appendfsync no,不主动刷盘,让操作系统自己刷,一般情况Linux:会每30秒刷一次盘,这
种策略下,可以说对性能的影响最小,但是如果发生崩溃,可能会丢失相对比较多的数据
| 策略 | 写回时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步写回 | 可靠性高,最大程度保证数据不丢失 | 每个写命令都要写回硬盘,性性能开销大 |
| Everysec | 每秒写回 | 性能适中 | 宕机时会丢失一秒的数据 |
| No | 由操作系统控制写回,liux一般是30s | 性能好 | 宕机时会丢失很多的数据 |
25. 缓存的几种模式
- Catch-Aside Pattern:旁路缓存模式
- 读模式:首先检查数据是否在缓存中,如果在的话直接返回相应结果;不在的话就去查库,查到后更新缓存,然后返回结果
- 写模式:更新数据库,然后直接删除缓存
- 适用于读多写少的情况,会出现缓存与数据库不一致的情况
- Read Through Cache Pattern:读穿透模式
- 与Catch Aside模式一样,只不过在读数据时并不是直接访问缓存,而是通过一个数据服务间接访问缓存和数据库
- Write Through Cache Pattern:写穿透模式
- 也是有一层数据服务,在写入数据时会由存储服务先写入数据库,再同步更新 Redis,及时加载和更新缓存
- 这种也是对缓存的及时性要求更高的,也会产生时序问题
- Write Behind Pattern:又叫Write Back,异步缓存写入模式
- 与 Write Through 不同的是 Write Behind 会先写缓存,再异步写数据库。值得注意的是写入数据库可以是收集写入数据,在某一时刻数据库负载低的时刻慢慢写入,也可以是合并几个写操作一起批量写入。
26. 几种限流算法
- 计数器算法:实现简单,但是会有请求突刺
- 滑动窗口算法:计数器算法的升级版,可以用 ZSet 实现,count 放时间戳,统计时用 ZCOUNT 即可
- 漏桶算法:入流量不固定,但出的是固定的。仅当桶中可以接受的时候才继续接水,否则拒绝。
- 令牌桶算法:类似于生产消费模型,相比于漏桶算法令牌桶算法能够容忍突发流量
27. 主从模式
通过 slaveof 命令开启,如:
1 | |
给 Redis 加上从节点,这样当 Master 挂了依然可以用从节点取而代之
28. 哨兵模式
可以监测节点故障并提供故障转移的能力。
29. Redis 集群
修改配置文件
1
2
3
4
5
61. 开启集群
cluster-enabled yes
2. 修改端口为目标端口
port 6379
3. dir 改为 './',表示在当前目录下
dir ./连接 Redis 组成集群
查看节点
1
2
3通过这个命令查看节点信息,包括有几个节点和他们被分配的哈希槽范围
127.0.0.1:6379> cluster nodes
由于没有连接其他节点所以只会有一个连接节点
1
2
3
4使用 cluster meet 命令连接其他节点
127.0.0.1:6379> cluster meet 127.0.0.1 6380
OK
这样就连接成功分配哈希槽
1
2
3
4
5
6
7
8
9
10
11
12
13分配哈希槽命令:
redis-cli -c -h <host> -p <port> cluster addslots <slot_range>
举例:
redis-cli -c -h 127.0.0.1 -p 6379 cluster addslots 1000
redis-cli -c -h 127.0.0.1 -p 6379 cluster addslots {0..5461}
从现有节点中取哈希槽分配给新节点:
redis-cli --cluster reshard target_node --cluster-from source_node --cluster-slots <slot_num>
举例:
从6380中取最小部分的100个哈希槽给6381
redis-cli --cluster reshard 127.0.0.1:6381 --cluster-from 127.0.0.1:6380 --cluster-slots 100
从现有的所有节点中取小的部分50个哈希槽给6381
redis-cli --cluster reshard 127.0.0.1:6381新节点加入
1
2
3
4先连接
127.0.0.1:6379> cluster meet 127.0.0.1 6381
分配一些哈希槽
redis-cli --cluster reshard 127.0.0.1:6381