Redis
本文最后更新于 2024年5月13日 晚上
Redis
Redis 缓存
缓存的定义
什么是缓存
缓存就是数据交换的缓冲区(称作Cache),是储存数据的临时地方,一般读写性能比较高
缓存的作用
- 降低后端负载
- 提高读写效率。降低响应时间
缓存的成本
- 数据一致性成本
- 代码维护成本
- 运维成本
Redis 缓存的策略及三个问题
缓存更新策略
三种方式
内存淘汰
说明:不用自己维护,利用 Redis 的内存淘汰机制,当内存不足时自动淘汰部分数据,下次查询时更新缓存。
一致性:差
维护成本:无
超时剔除
说明:给缓存数据添加 TTL,到期后自动删除缓存。下次查询时更新缓存。
一致性:一般
维护成本:低
主动更新
说明:编写业务逻辑,再修改数据库的同时,更新缓存。
一致性:好
维护成本:高
主动更新策略有三个问题
- 删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都更新缓存,无效写操作比较多 ❌
- 删除缓存:更新数据库时让缓存失效,查询时在更新缓存 ✔
- 如何保证缓存与数据库的操作同时成功或失败?(原子性)
- 单体系统:将缓存与数据库操作放在同一个事务
- 分布式系统:利用 TCC 等分布式事务方案(TCC是Try、Confirm、Cancel三个词语的缩写,TCC要求每个分支事务实现三个操作:预处理Try、确认 Confirm、撤销Cancel。Try操作做业务检查及资源预留,Confirm做业务确认操作,Cancel实现一个与Try相反的 操作即回滚操作。TM首先发起所有的分支事务的try操作,任何一个分支事务的try操作执行失败,TM将会发起所 有分支事务的Cancel操作,若try操作全部成功,TM将会发起所有分支事务的Confirm操作,其中Confirm/Cancel 操作若执行失败,TM会进行重试。)
- 先操作缓存还是数据库?(线程安全问题)
- 先删除缓存,再操作数据库 ❌
- 先操作数据库,再删缓存 ✔
- 因为读写缓存的速度远远高于读写数据库的速度,所以第二种方案线程安全的概率相对较低
业务场景:
- 低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存。
- 高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存。
- 读操作:
- 缓存命中直接返回
- 若缓存未命中则查询数据库,并写入缓存,设定超时时间
- 写操作
- 先写数据库,然后再删除缓存
- 要确保数据库与缓存操作的原子性
- 读操作:
缓存穿透
定义:缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
常见的两种解决方案
- 缓存空对象
- 方法:通过缓存 null 的方式,让这些请求不会到达数据库
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致

- 布隆过滤
- 优点:内存占用较少,没有多余 key
- 缺点:
- 实现复杂
- 存在误判的可能
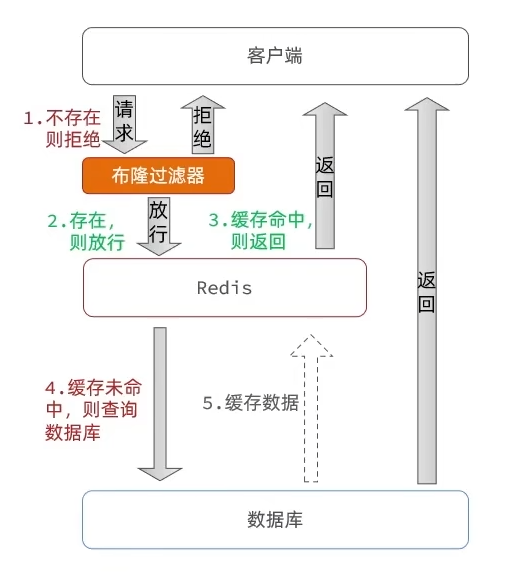
总结:
- 缓存穿透产生的原因是什么:
- 用户请求的数据在缓存中和在数据库中都不存在,不断发起这样的请求会给数据库带来巨大压力
- 缓存穿透的解决方案有哪些:
- 缓存 null 值:简单粗暴,便于维护;但会给内存带来压力以及短暂的不一致性
- 布隆过滤:内存压力小,准确性不能保证
- 增加 id 复杂度,避免被猜测 id 规律
- 做好数据的基础格式校验
- 加强用户权限管理
- 做好热点参数限流
缓存雪崩
定义:缓存雪崩是指在同一时段,大量的缓存 key 同时失效或者 Redis 服务宕机,导致大量请求到达数据库,带来巨大压力
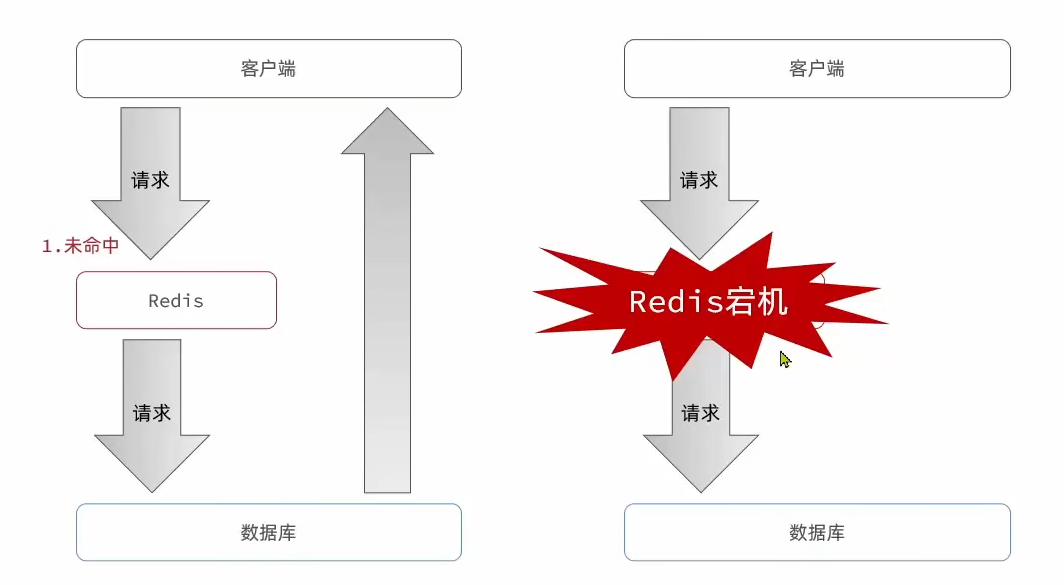
解决方案
- 给不同的 Key 的 TTL 添加随机值
- 利用 Redis 集群提高服务的可用性
- 该缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
定义:缓存击穿问题也叫热点 Key 问题,就是一个被高并发访问并且缓存重建业务较复杂的 Key 突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的两种解决方案
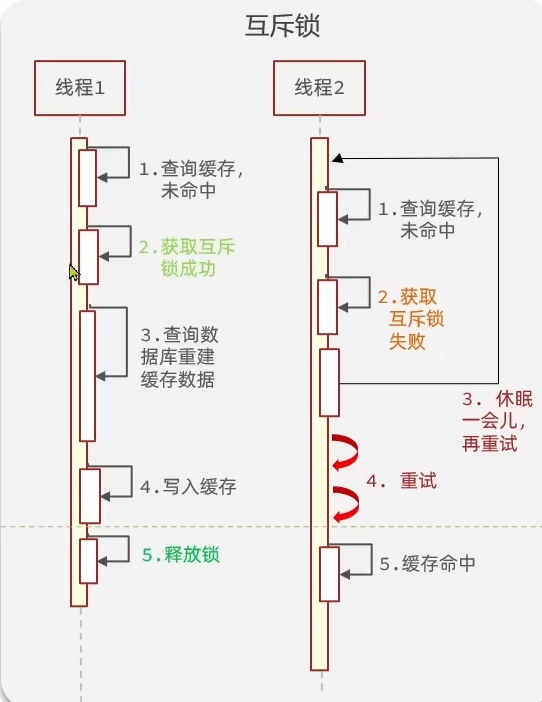
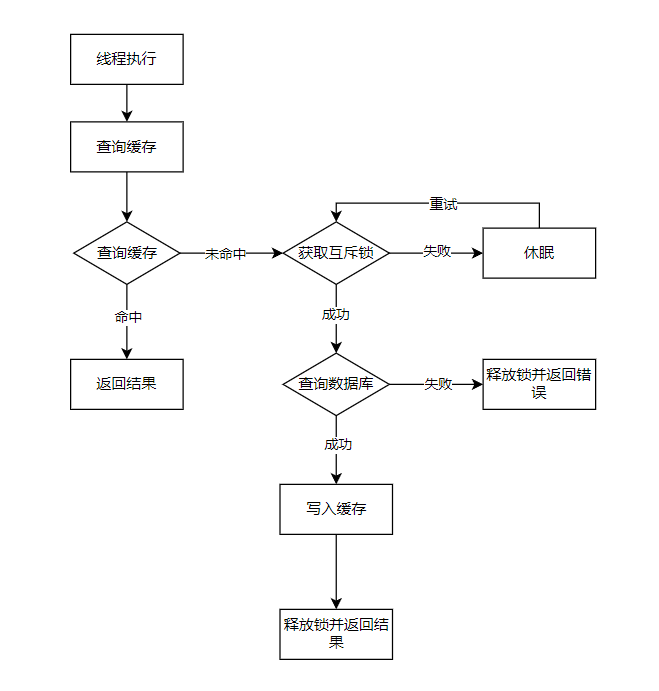
- 互斥锁
- 优点:
- 没有额外的内存消耗
- 保证一致性
- 实现简单
- 缺点:
- 线程需要等待
- 可能有死锁风险
- 优点:
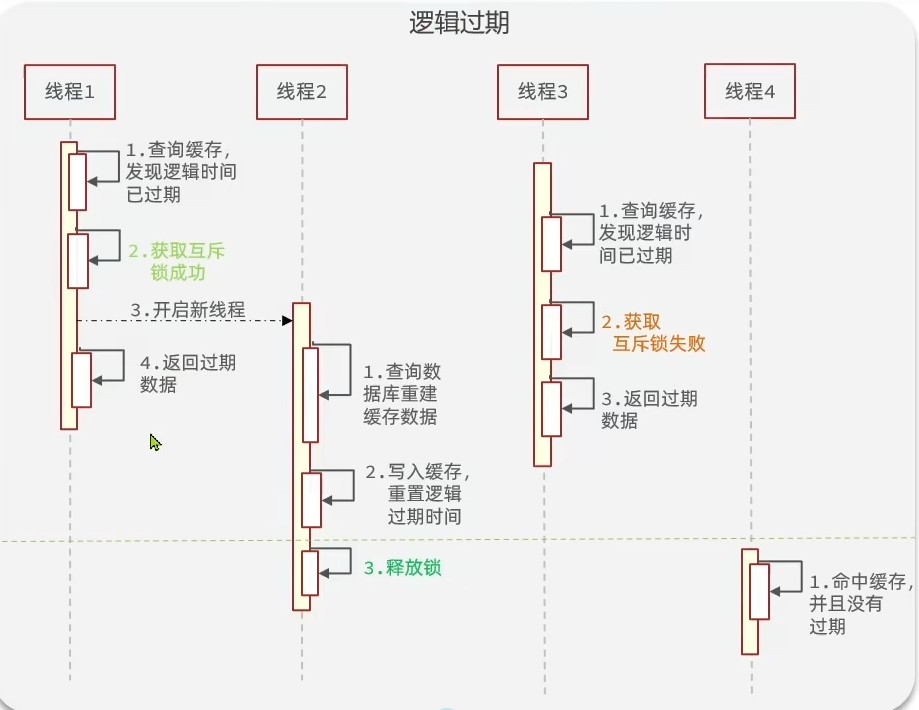
- 逻辑过期
- 优点:线程无需等待,性能较好
- 缺点:
- 不保证一致性
- 有额外内存消耗
- 实现复杂

数据同步相关知识
悲观锁和乐观锁概念
悲观锁
认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行
例如 Synchornized、Lock 都属于悲观锁
优点:简单粗暴
缺点:降低性能
乐观锁
认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其它线程对数据做了修 改。
如果没有修改则认为是安全的,自己才更新数据。
如果已经被其它线程修改说明发生了安全问题,此时可以重试或异常
关键在于判断之前查询得到的数据是否有被修改过
优点:性能好
缺点:存在成功率降低的问题
乐观锁的实现方法
- 版本号法
- 在线程执行最初先查库存和版本号
- 在执行更新SQL时在SQL中要判断修改的版本号与最初查询的是否一致
- 加上的条件类似于
set ... where id=10 and version=xxx
- CAS法
- 是版本号法的简化版
- 如果有数据能与版本号一样唯一,比如商品库存是固定的,那么库存就是唯一的,那么库存和版本号就可以简化为直接用库存
集群模式下的多线程问题
- 由于是多台服务器,因此有多个 JVM,而每个 JVM 有独立的锁监视器,因此在集群的情况下使用 synchornized 加锁依旧会出现线程安全问题。
分布式锁
分布式锁定义:满足分布式系统或集群模式下多进程可见并且互斥的锁
实现分布式锁需要实现的两个方法:
获取锁
互斥:确保只有一个线程能获取锁,可以使用 redis 的 SETNX 来实现
1
SETNX lock thread1非阻塞:尝试一次,成功返回 true,失败返回 false
释放锁
手动释放
1
DEL key超时释放:获取锁时添加一个超时时间
使用 Redisson 的分布式锁
基础使用
引入 redisson
1
2
3
4
5<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.17.5</version>
</dependency>配置 RedissonConfig
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33@Configuration
@ConfigurationProperties(prefix = "spring.redis")
@Data
public class RedissonConfig {
private String host;
private String port;
private String password;
private int redissonDatabase;
@Bean
public RedissonClient redissonClient() {
// 1. 创建配置
Config config = new Config();
String redisAddress = String.format("redis://%s:%s", host, port);
// 开发
config
.useSingleServer()
.setAddress(redisAddress)
.setDatabase(redissonDatabase);
// 生产
//config
//.useSingleServer()
//.setAddress(redisAddress)
//.setDatabase(redissonDatabase)
//.setPassword(password);
// 2. 创建实例
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}使用分布式锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public void createTeam(Team team, User user) {
RLock lock = redissonClient.getLock("team:createTeam:lock");
try {
if (lock.tryLock(0, -1, TimeUnit.MILLISECONDS)) {
...
} catch (InterruptedException e) {
// 处理
} finally {
// 只能释放自己的锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}参数解释:
- tryLock(l, l1, TimeUnit)
- l: 尝试获取锁的时间,如果在时间内会重复尝试获取锁,超时就获取锁失败
- l1: 锁过期的时间,可以不写,默认是 -1, 虽然是 30s, 但是由于看门狗机制,每过 10s 都会将时间刷新为 30s
- TimeUnit: java.util.concurrent 包中的时间单位,例如
TimeUnit.MILLISECONDS
- lock.isHeldByCurrentThread()
- 顾名思义,判断是否是当前线程的锁
- lock.unlock()
- 解锁
- tryLock(l, l1, TimeUnit)
Redisson 分布式锁主从一致性问题
Redis 可以让所有节点都成为主节点,每次获取锁要向所有节点获取锁成功才算成功,这样就解决了主从一致性问题,同时还保证了可用性。
可以在上一步的基础上建立主从同步
利用创建联锁 multiLock 的方式来实现(前提是在 config 里已经声明了同名 Bean)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17@Resource
private RedissonClient redissonClient;
@Resource
private RedissonClient redissonClient2;
@Resource
private RedissonClient redissonClient2;
void test() {
RLock lock1 = redissonClient.getLock("lock");
RLock lock2 = redissonClient2.getLock("lock");
RLock lock3 = redissonClient3.getLock("lock");
// 创建联锁
lock = redissonClient.getMultiLock(lock1, lock2, lock3);
}
Redis优化秒杀
在 java 中使用 lua 脚本
注意:lua 脚本放在 resources 文件夹下即可直接使用 ClassPathResource(文件名)读取,否则要用绝对路径
1 | |
使用阻塞队列实现异步秒杀
阻塞队列
阻塞队列是一种特殊的队列,同样遵循“先进先出”的原则,支持入队操作和出队操作。在此基础上,阻塞队列会在队列已满或队列为空时陷入阻塞,使其成为一个线程安全的数据结构,它具有如下特性:
当队列已满时,继续入队列就会阻塞,直到有其他线程从队列中取走元素。
当队列为空时,继续出队列也会阻塞,直到有其他线程向队列中插入元素。
初始化示例:
1 | |
标准库中的阻塞队列种类
类名 说明 LinkedBlockingQueue<> 基于链表的阻塞队列(常用) LinkedBlockingDeque<> 基于链表的双端阻塞队列 LinkedTransferQueue<> 基于链表的无界阻塞队列 ArrayBlockingQueue<> 基于数组的阻塞队列 PriorityBlockingQueue<> 带有优先级功能的阻塞队列 常用方法
方法 解释 void put(E e) 带有阻塞特性的入队操作方法(常用) E take() 带有阻塞特性的出队操作方法(常用) boolean offer(E e, long timeout, TimeUnit unit) 带有阻塞特性的入队操作方法,并且可以设置最长等待时间 E poll(long timeout, TimeUnit unit) 带有阻塞特性的出队操作方法,并且可以设置最长等待时间 public boolean contains(Object o) 判断阻塞队列中是否包含某个元素
实现异步秒杀
思想:主线程将订单存入阻塞队列中,另开其他线程处理阻塞队列的订单,实现异步处理
代码示例:
1 | |
使用消息队列实现异步秒杀
消息队列
消息队列(Message Queue/MQ):是一种进程间通信或同一进程的不同线程间的通信方式。被广泛应用为分布式服务框架的消息中间件。
最简单的消息队列模型包括三个角色:
- 生产者(Producer)业务的发起方,负责生产消息发布给Broker。
- 消费者(Consumer)业务的处理方,负责从Broker订阅消息并进行业务逻辑处理。
- 消息队列(Message Broker)MQ的服务器。包括接收 Producer 发过来的消息、处理 Consumer 的消费消息请求、消息的持久化存储、以及服务端过滤功能等,也被称为消息代理。

Redis提供了三种不同的方式来实现消息队列:
- list 结构:基于 list 结构模拟消息队列
- PubSub:基本的点对点消息模型
- Stream:比较完善的消息队列模型
基于 List 结构模拟消息队列
队列时入口和出口不在一边,因此我们可以用:LPUSH 结合 RPOP 或者 RPUSH 结合 LPOP 来实现。
不过要注意的是,当队列中没有消息时 RPOP 或 LPOP 操作会返回 null, 并不像 JVM 的阻塞队列那样会阻塞并等待消息。因此这里应该使用 BRPOP 或者 BLPOP 来实现阻塞效果。
优点:
- 利用 Redis 存储,不受限于 JVM 内存上限
- 基于 Redis 的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点
- 无法避免消息丢失
- 只支持单消费者
基于 PubSub 的消息队列
PubSub(发布订阅)是 Redis2.0 版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个 channel,生产者向对应 channel 发送消息后,所有订阅者都能收到相关信息。
- SUBSCRIBE channel [channel]:订阅一个或多个频道
- PUBLISH channel msg:向一个频道发送消息
- PSUBSCRIBE pattern [pattern]:订阅与 pattern 格式匹配的所有频道
- h?llo subscribes to hello, hallo, hxllo…
- h*llo subscribes to hello, heeello…
- h[ae]llo subscribes to hallo and hello
优点:
- 采用发布订阅模型,支持多生产,多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
基于 Stream 的消息队列
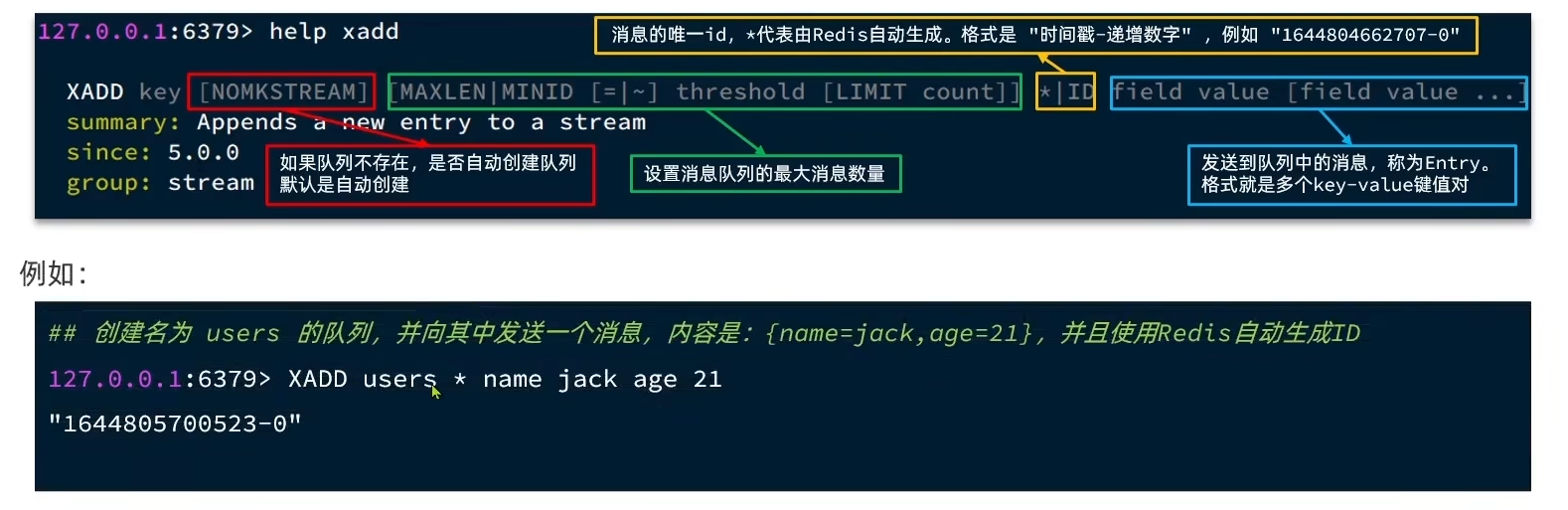
Stream 是 Redis 5.0 引入的一种新的数据类型,可以实现一个功能非常完善的消息队列。
发送消息的命令 XADD:XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value …]
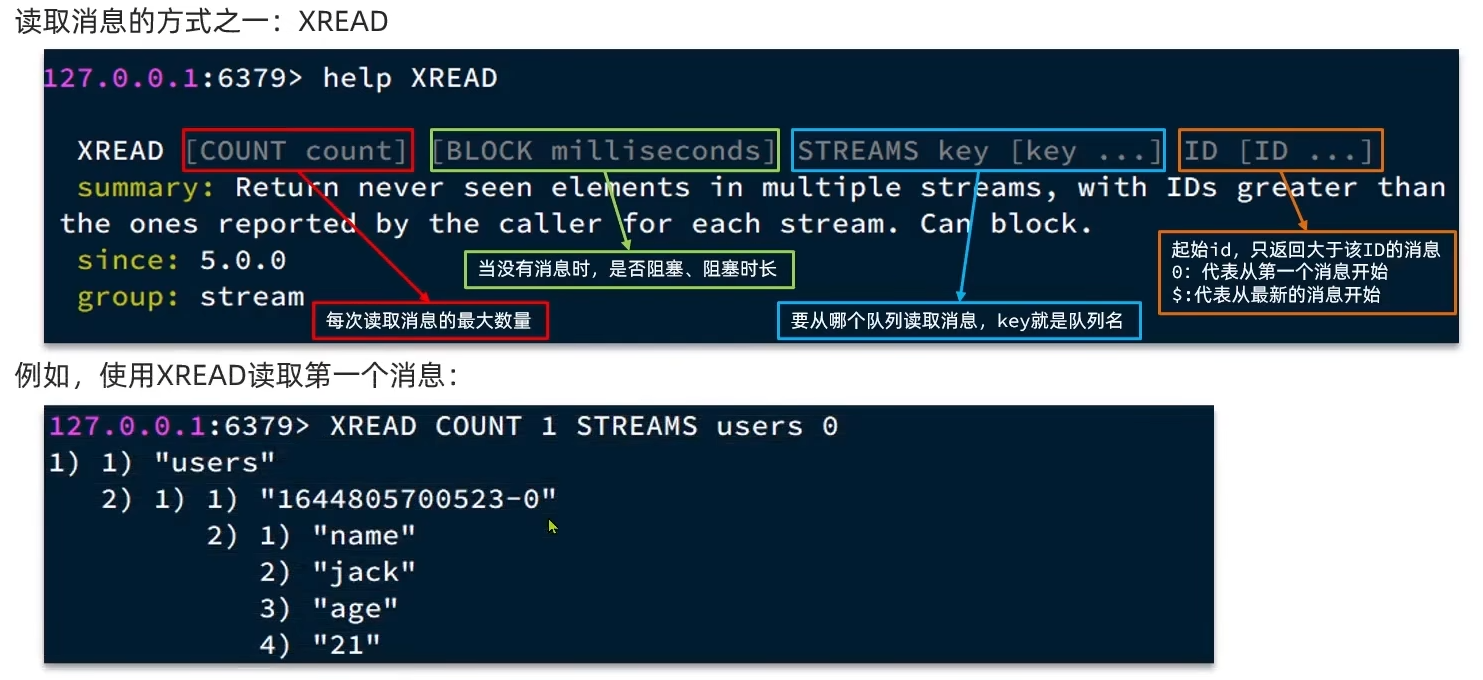
读取消息的命令之一:XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key …] ID [ID …]
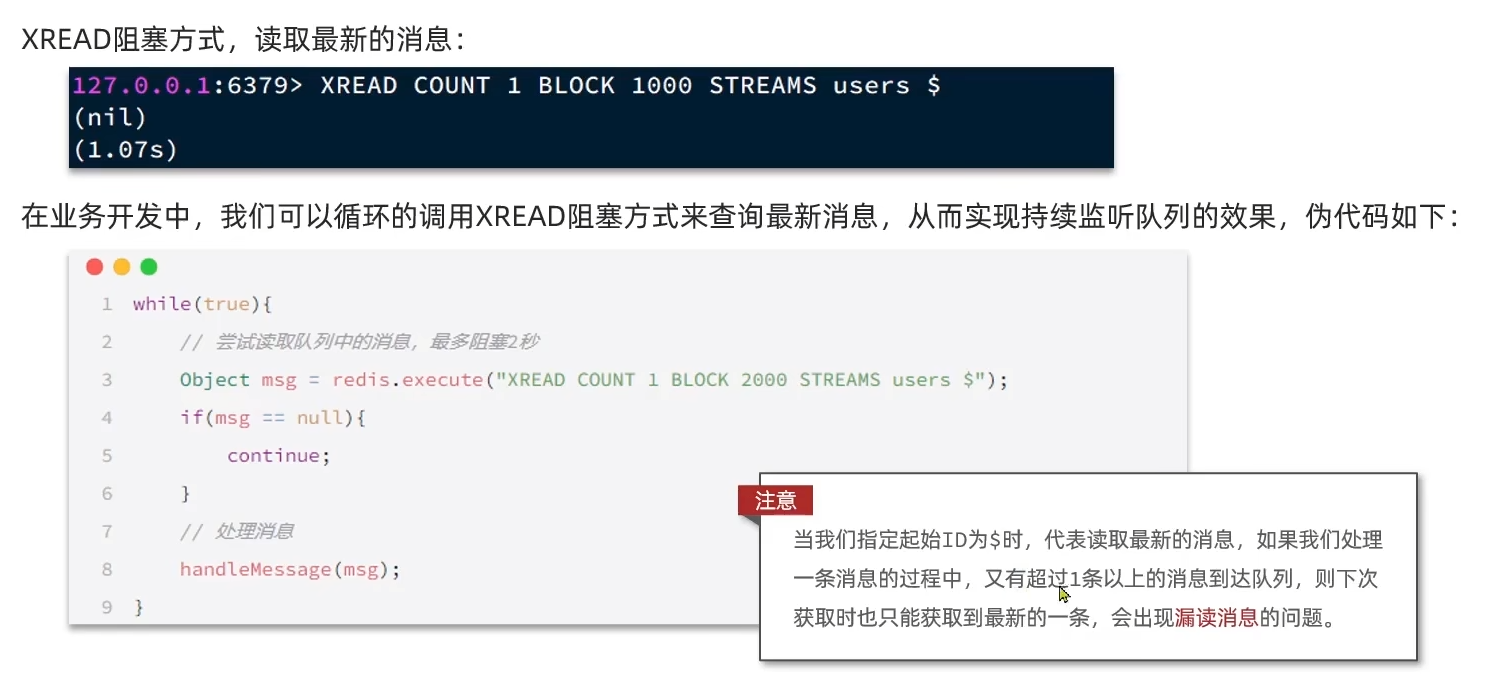
XREAD 命令特点:
- 消息可回溯
- 一个消息可被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
基于 Stream 的消息队列 - 消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。
特点:
- 消息分流:队列中的消息会分流给组内的不同消费者,而不是重复消费,从而加快消息处理的速度。
- 消息标示:消费者组会维护一个标示,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标示之后读取消息。确保每一个消息都会被消费。
- 消息确认:消费者获取消息后,消息处于 pending 状态,并存入一个 pending-list。当处理完成后需要通过 XACK 来确认消息,标记消息为已处理,才会从 pending-list 移除。
创建消费者组:XGROUP CREATE key groupName ID [MKSTREAM]
- key:队列名称
- groupName:消费者组名称
- ID:起始ID标识,$代表队列中最后一个消息,0则是代表队列中第一个消息
- MKSTREAM:队列不存在时自动创建队列
- 其他常见命令:
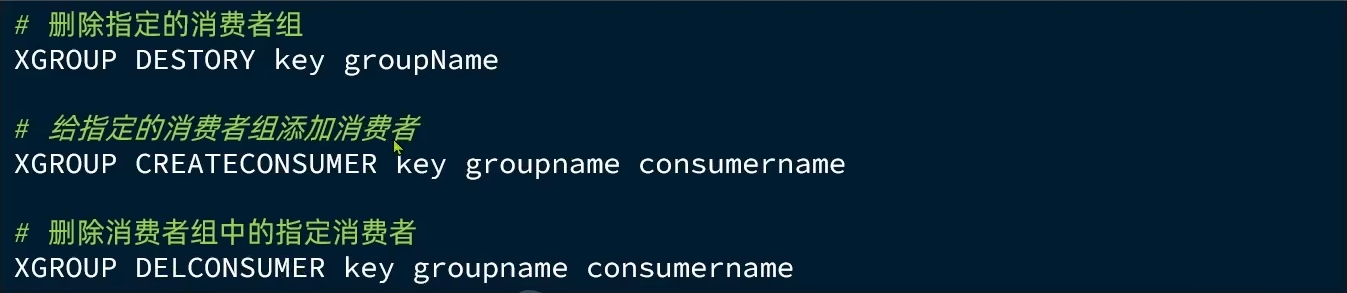
从消费者组读取消息:XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key …] ID [ID …]
- group:消费者组名称
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count:本次查询最大数量
- BLOCK milliseconds:当没有消息时最长等待时间
- NOACK:无需手动ACK,获取到消息后自动确认
- STREAMS key:指定队列名称
- ID:获取消息的起始ID
">":从下一个未消费的消息开始(建议使用)- 其它:根据指定 id 从 pending-list 中获取已消费但未确认的消息,例如0,是从 pending-list 中的第一个
消息开始,或者是具体的 id 如:************-*
- 特点:
- 消息可回溯
- 可以多消费者争抢信息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
确认消息:XACK key GROUP ID [ID …]
- key:队列名称
- GROUP:消费者组名称
- ID:获取消息的起始ID或ID集合
获取 pending-list 中的消息:XPENDING key group [[IDLE min-idle-time] start end count [consumer]]
- key:队列名称
- GROUP:消费者组名称
- IDLE min-idle-time:获取消息后直到确认前的时间,空闲时间
- start:最小ID
- end:最大ID
- count:获取消息的数量
- consumer:指定某个消费者
java 使用代码示例:
1 | |
总结
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |